

How To Install Xlwt Python In Windows
With the advent of the era of large data, the need for network information has increased widely. Many different companies collect external information from the Internet for various reasons: analyzing competition, summarizing news stories, tracking trends in specific markets, or collecting daily stock prices to build predictive models. Therefore, web crawlers are condign more than important. Web crawlers automatically browse or grab information from the Internet according to specified rules.
Classification of web crawlers
According to the implemented engineering science and structure, spider web crawlers can exist divided into general web crawlers, focused web crawlers, incremental web crawlers, and deep web crawlers.
Basic workflow of web crawlers
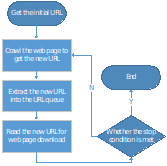
Basic workflow of general web crawlers
The basic workflow of a general web crawler is as follows:
-
Get the initial URL. The initial URL is an entry bespeak for the web crawler, which links to the web page that needs to be crawled;
-
While crawling the web page, we need to fetch the HTML content of the page, then parse it to get the URLs of all the pages linked to this folio.
-
Put these URLs into a queue;
-
Loop through the queue, read the URLs from the queue one by one, for each URL, crawl the corresponding web page, then echo the above itch process;
-
Check whether the stop condition is met. If the finish status is not set, the crawler will keep crawling until information technology cannot get a new URL.
Ecology preparation for spider web crawling
-
Make sure that a browser such equally Chrome, IE or other has been installed in the environment.
-
Download and install Python
-
Download a suitable IDL
This article uses Visual Studio Code -
Install the required Python packages
Pip is a Python parcel management tool. It provides functions for searching, downloading, installing, and uninstalling Python packages. This tool will be included when downloading and installing Python. Therefore, we tin can directly employ 'pip install' to install the libraries nosotros demand.
ane 2 3pip install beautifulsoup4 pip install requests pip install lxml
• BeautifulSoup is a library for hands parsing HTML and XML data.
• lxml is a library to better the parsing speed of XML files.
• requests is a library to simulate HTTP requests (such every bit Become and POST). We volition mainly use it to access the source code of any given website.
The post-obit is an example of using a crawler to crawl the top 100 motion-picture show names and movie introductions on Rotten Tomatoes.
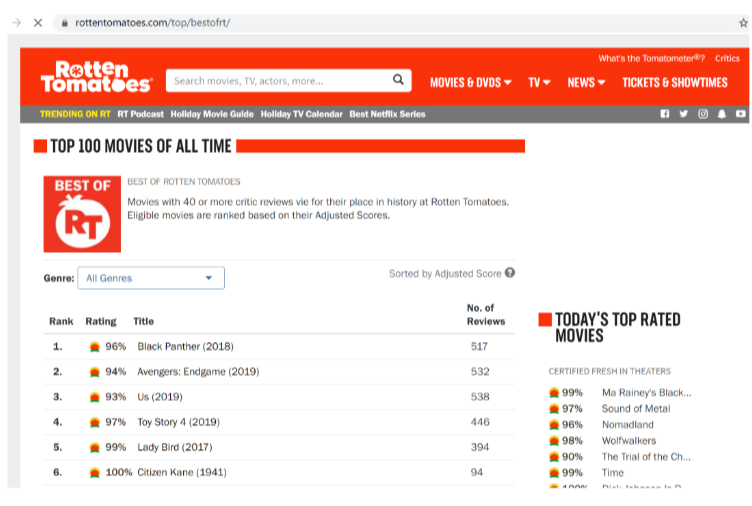
Top100 movies of all time –Rotten Tomatoes
We need to extract the name of the movie on this page and its ranking, and become deep into each pic link to get the movie'southward introduction.
one. First, y'all need to import the libraries you lot demand to use.
1 2 three 4import requests import lxml from bs4 import BeautifulSoup
2. Create and access URL
Create a URL address that needs to be crawled, so create the header information, and and then send a network asking to wait for a response.
1 2url = "https://www.rottentomatoes.com/top/bestofrt/" f = requests.go(url)
When requesting access to the content of a webpage, sometimes you lot will find that a 403 error will announced. This is because the server has rejected your admission. This is the anti-crawler setting used by the webpage to forbid malicious collection of information. At this time, y'all can admission information technology by simulating the browser header data.
1 two 3 4 5url = "https://world wide web.rottentomatoes.com/pinnacle/bestofrt/" headers = { 'User-Agent': 'Mozilla/five.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE' } f = requests.get(url, headers = headers)
3. Parse webpage
Create a BeautifulSoup object and specify the parser as lxml.
soup = BeautifulSoup(f.content,'lxml')
four. Extract information
The BeautifulSoup library has 3 methods to detect elements:
findall() :find all nodes
find() :observe a single node
select() :finds according to the selector CSS Selector
Nosotros need to get the name and link of the top100 movies. We noticed that the name of the pic needed is under
. After extracting the page content using BeautifulSoup, nosotros can utilise the notice method to extract the relevant information.
movies = soup.detect('table',{'class':'table'}).find_all('a')
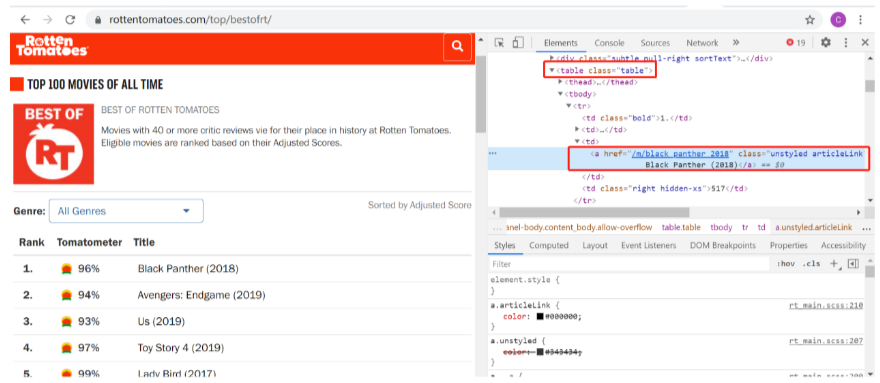
Get an introduction to each movie
After extracting the relevant data, you also need to extract the introduction of each movie. The introduction of the movie is in the link of each movie, so yous need to click on the link of each movie to get the introduction.
The lawmaking is:
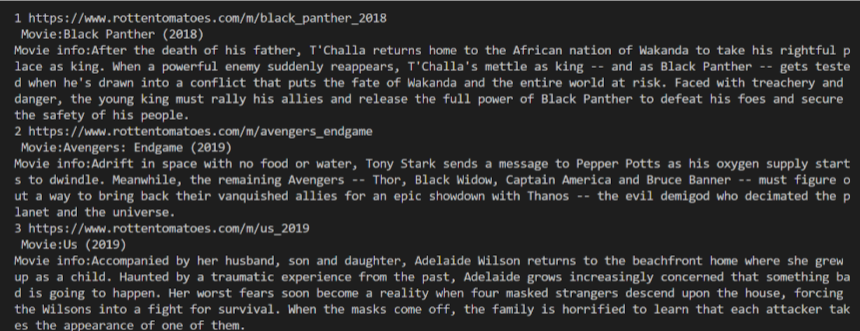
i 2 three 4 5 6 vii eight 9 x 11 12 13 xiv fifteen 16 17 xviii 19 20 21 22 23 24 25 26 27 28 import requests import lxml from bs4 import BeautifulSoup url = "https://www.rottentomatoes.com/top/bestofrt/" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT six.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE' } f = requests.go(url, headers = headers) movies_lst = [] soup = BeautifulSoup(f.content, 'lxml') movies = soup.find('tabular array', { 'class': 'table' }) .find_all('a') num = 0 for anchor in movies: urls = 'https://www.rottentomatoes.com' + anchor['href'] movies_lst.append(urls) num += 1 movie_url = urls movie_f = requests.get(movie_url, headers = headers) movie_soup = BeautifulSoup(movie_f.content, 'lxml') movie_content = movie_soup.find('div', { 'course': 'movie_synopsis clamp clamp-6 js-clamp' }) print(num, urls, '\n', 'Film:' + anchor.cord.strip()) impress('Movie info:' + movie_content.string.strip()) The output is:
Write the crawled data to Excel
In social club to facilitate data analysis, the crawled data can exist written into Excel. We utilize xlwt to write data into Excel.
Import the xlwt library.
from xlwt import *
Create an empty table.
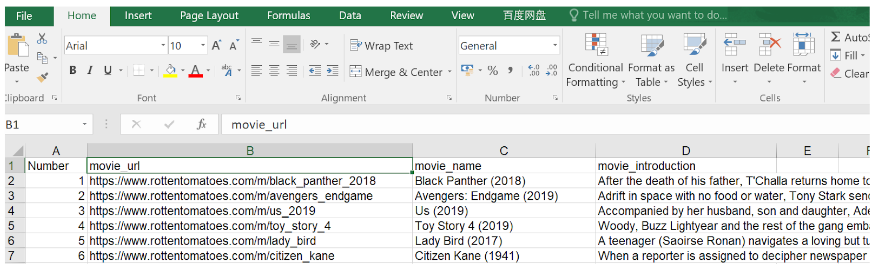
i 2 3 4 5 6 7 8 9 10 11 12 13 workbook = Workbook(encoding = 'utf-viii') tabular array = workbook.add_sheet('information') Create the header of each column in the first row. table.write(0, 0, 'Number') table.write(0, 1, 'movie_url') table.write(0, 2, 'movie_name') table.write(0, 3, 'movie_introduction') Write the crawled data into Excel separately from the second row. tabular array.write(line, 0, num) tabular array.write(line, 1, urls) table.write(line, 2, ballast.string.strip()) table.write(line, 3, movie_content.string.strip()) line += 1 Finally, save Excel.
workbook .salve('movies_top100.xls')
The final lawmaking is:
ane 2 3 four v 6 7 8 9 10 eleven 12 13 fourteen fifteen 16 17 18 nineteen 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 xl 41 42 43 import requests import lxml from bs4 import BeautifulSoup from xlwt import * workbook = Workbook(encoding = 'utf-viii') tabular array = workbook.add_sheet('data') table.write(0, 0, 'Number') table.write(0, ane, 'movie_url') table.write(0, 2, 'movie_name') table.write(0, 3, 'movie_introduction') line = 1 url = "https://world wide web.rottentomatoes.com/meridian/bestofrt/" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE' } f = requests.get(url, headers = headers) movies_lst = [] soup = BeautifulSoup(f.content, 'lxml') movies = soup.find('table', { 'class': 'table' }) .find_all('a') num = 0 for anchor in movies: urls = 'https://www.rottentomatoes.com' + anchor['href'] movies_lst.suspend(urls) num += 1 movie_url = urls movie_f = requests.get(movie_url, headers = headers) movie_soup = BeautifulSoup(movie_f.content, 'lxml') movie_content = movie_soup.discover('div', { 'class': 'movie_synopsis clamp clamp-half dozen js-clamp' }) print(num, urls, '\n', 'Picture:' + anchor.string.strip()) print('Motion-picture show info:' + movie_content.cord.strip()) table.write(line, 0, num) table.write(line, i, urls) table.write(line, 2, ballast.string.strip()) table.write(line, three, movie_content.cord.strip()) line += 1 workbook.relieve('movies_top100.xls') The result is:
Chat on Discord
Source: https://www.topcoder.com/thrive/articles/web-crawler-in-python
Posted by: dahlstromwhalke38.blogspot.com
0 Response to "How To Install Xlwt Python In Windows"
Post a Comment